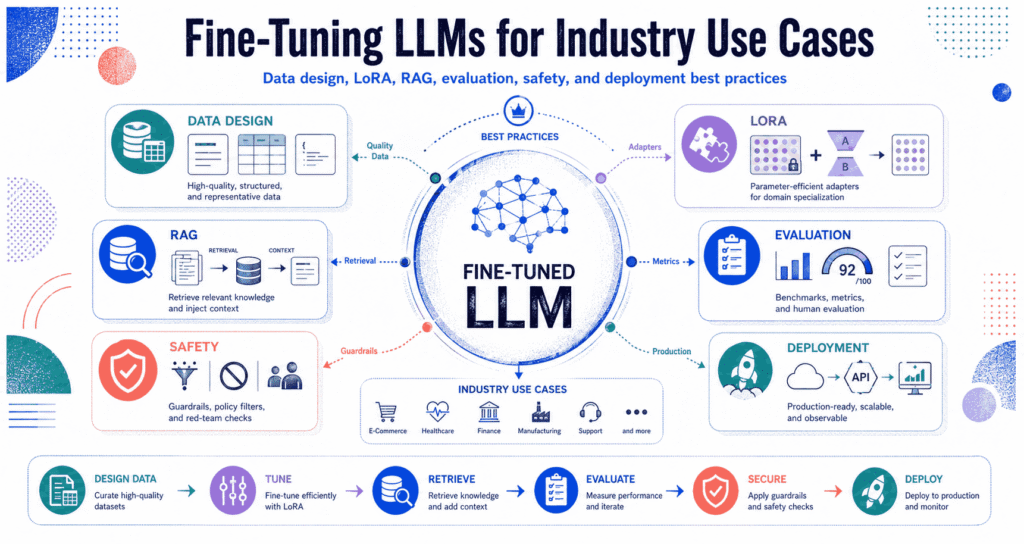
Fine tuning LLMs forces a generic language model to actually care about your specific job. You stop begging a chatbot to follow instructions through massive text prompts, and instead, you literally rewire its brain with hard examples—pushing it to spit out exact formats without complaining. It just works.
Why Fine Tuning LLMs Matters for Industry Use Cases
Off-the-shelf bots talk too much. A hospital or a law firm does not want conversational filler—they need exact medical billing codes, strict contract clauses, and rigid approval limits mapped out perfectly, which means a chatbot that sounds incredibly smart will still get you fired if it ignores your compliance limits. Lock it down.
Prompts break constantly. If you need to drop fifty angry customer emails into a strict internal ticketing system, or force a script to rip doctor notes into a billing spreadsheet without making up fake symptoms—you have to bake those rules directly into the weights. You cannot just ask nicely.
Stop trying to build a digital god. You are not trying to teach a computer everything there is to know about the modern financial system. You just want it to fill out the 1040 tax form exactly the same way every single time.
The golden rule: tune the machine to fix its attitude. Plug in a search engine (like RAG) to feed it actual facts.
Fine-Tuning Is Not the Same as Prompt Engineering
Prompts are just sticky notes. You type out a massive block of rules every single time you hit enter, hoping the machine actually reads the instructions instead of ignoring them completely. It is incredibly cheap.
Tuning rewires the brain entirely. You feed the system thousands of perfect examples—showing it exactly what good work looks like—so you can finally stop typing out five-page instruction manuals every single time you want a simple JSON output. It saves massive amounts of time.
But here is the catch—if you feed it garbage, it learns garbage. Dump a spreadsheet full of spelling errors and conflicting rules into the training script, and you will just end up with an incredibly expensive machine that generates spelling errors on command.
| Approach | Best for | What changes | Main risk |
|---|---|---|---|
| Prompting | Fast tests, text fixes | The prompt text | Long text blocks fail randomly |
| RAG | Searching private files | The data it reads | Bad searches ruin the answer |
| Fine-tuning | Locking down formats | The brain wires | Garbage data breaks the bot |
| Full system | Enterprise workflows | Everything combined | Hard to build and watch |
When Should You Fine-Tune an LLM?
Stop rushing the process. If your team changes its mind about the final output format every three days, stick to basic text prompts—you only pull the trigger on a real training run when you have a massive pile of completely perfect examples locked in. Wait it out.
Vague goals kill projects instantly. Asking a machine to “act like a lawyer” is a complete joke, but ordering it to “rip the liability clauses out of this PDF and format them into a three-column table” is a job you can actually train and measure. Be brutally specific.
Do the math first. If you only run the script twice a week, just use a long prompt. But if you get slammed with ten thousand customer emails a day, baking the rules into the model cuts your server bills in half.
- Tune it to force an exact format.
- Tune it to stop the weird guessing.
- Tune it when you have perfect data to show it.
- Skip it if you just need to search for facts.
- Skip it if your boss keeps changing the rules.
The Industry Fine-Tuning Pipeline
Treat this like a data cleanup job. If you just dump a random zip file of past chats into the training folder and hit run, you will completely ruin the model. Clean the mess.
the job
the files
the data
the math
the bot
Write the rules down on paper. You have to map out exactly what the machine is allowed to touch, what it needs to ignore completely, and how you plan to grade the final test—and then you build your training files to match those exact rules.
Hide the final exam. You absolutely must lock a chunk of your data away in a separate folder so the machine never sees it during the training loop—otherwise, it just memorizes the answers and lies to you about how smart it is.
Step 1: Define the Industry Use Case Properly
Ambition ruins everything here. Teams desperately try to build one single bot that handles tech support, writes marketing emails, and balances the accounting books—which leaves them with a totally useless machine that does all three jobs terribly. Pick one job.
Break it down to the absolute basics. You need to know exactly who is typing the prompt, what the raw file looks like, and exactly what the final output needs to say—like forcing a banking bot to spit out a fraud score without accidentally accusing an innocent customer of a felony.
| Industry | Good fine-tuning task | Poor fine-tuning task |
|---|---|---|
| Healthcare | Turn doctor notes into patient summaries. | Build an AI doctor. |
| Legal | Format liability tables. | Answer legal questions. |
| Finance | Tag angry support tickets. | Understand Wall Street. |
| Retail | Fix product descriptions. | Drive all sales. |
Step 2: Build the Right Training Dataset
Show it what you want. You literally just hand it a giant list of bad inputs matched with perfect outputs—whether that means chat logs, JSON extractions, or completely rewritten emails.
Stop hoarding garbage. A thousand perfectly typed examples will always beat a million random support tickets—especially if those old tickets are packed with spelling errors, dead links, and angry employees handing out totally wrong advice. Scrub the files.
Mix it up completely. You have to feed it the weird edge cases, the broken files, and the total nonsense prompts—specifically to teach the bot how to completely shut down and refuse to answer when a user tries to trick it.
{
"messages": [
{
"role": "system",
"content": "You are an insurance claim summarization assistant. Follow the approved claim summary format."
},
{
"role": "user",
"content": "Customer reports water damage in kitchen after pipe leak. Photos attached. Repair estimate submitted."
},
{
"role": "assistant",
"content": "Claim Type: Property Damage\nCause: Reported pipe leak\nCurrent Evidence: Customer photos and repair estimate\nNext Action: Review policy coverage and validate repair estimate\nRisk Notes: No fraud indicators stated in the provided note."
}
]
}
Look at that last line. If you run a bank or a hospital, you absolutely cannot have a machine hallucinating fake risk signals just to sound helpful. Restraint saves you from lawsuits.
Step 3: Choose the Right Fine-Tuning Technique
You have options here. The exact math you use completely depends on how much cash you want to burn on servers and whether or not you are legally allowed to push your private data into the cloud.
Most people just use standard supervised learning. You just shove the right answers into the system until it gets the point, but if you need to teach it sarcasm or politeness, you have to run preference models to slowly nudge the tone in the right direction. It takes time.
Running full updates on open-source models will instantly melt your GPU. You have to cheat the system by running LoRA or QLoRA—which basically bolts a tiny, cheap patch onto the side of the massive brain instead of rewriting the whole thing from scratch. Check the Hugging Face PEFT documentation for the exact scripts.
| Technique | How it works | Best for | Tradeoff |
|---|---|---|---|
| Supervised | Feeds it perfect examples. | Forms and tagging. | You have to clean the data. |
| LoRA | Bolts a small patch onto the brain. | Cheap open-source runs. | The patch might fail. |
| QLoRA | Crushes the memory down. | Running on bad hardware. | Hard to set up right. |
| Preference | Scores the tone. | Fixing the attitude. | Needs humans to judge it. |
The massive cloud providers will just do the math for you. You can hit up OpenAI’s supervised fine-tuning guide or use Amazon Bedrock model customization to let their servers handle the heavy lifting while you just worry about the data.
Fine-Tuning vs RAG for Industry Knowledge
This is the biggest mistake in the industry. People desperately try to train these models to memorize the entire company rulebook, completely forgetting that the second the HR team updates the vacation policy, the massive AI brain is suddenly lying to every single employee. You cannot hardcode facts.
Hook up a search engine instead. Let a RAG pipeline dig up the PDF file the second a user asks a question, and only use the actual training runs to teach the bot exactly how to format the final answer.
You absolutely must bolt them together. You train the bot to act like a paranoid compliance officer, and then you wire it into a live database so it always reads the fresh data before speaking. Check Codeayan’s breakdown on Agentic RAG to see how the loops work.
The cheat code: if the facts change, search for them. If the layout stays the same, train for it.
Industry Examples of Fine-Tuned LLMs
In hospitals, you train the machine to rip terrible doctor handwriting into clean discharge papers without letting it randomly invent a totally fake cancer diagnosis. You have to watch it constantly.
Law firms use them to crush massive contracts down into quick bullet points. The bot doesn’t actually practice law, but it saves the junior associates from reading three hundred pages of boilerplate liability text at midnight.
Finance teams use the math to sort angry emails into fraud buckets. The only rule is keeping the language locked down—because you absolutely cannot have a machine automatically accusing a user of a federal crime without proof.
Retailers just use them to write product tags. This is honestly the safest bet out there, because if a bot accidentally uses the wrong adjective to describe a winter coat, absolutely no one goes to jail.
Factory floors push technician logs into safety reports. The system learns the exact acronyms for the heavy machinery and spits out the compliance forms without adding fake maintenance steps.
Evaluation: The Most Important Part of Fine-Tuning
Running a training loop without testing it is completely idiotic. You have to run the numbers to see if the expensive new brain actually beats a standard prompt before you start bragging to your boss about the results.
Pull up the hidden test files. You throw the fresh questions at the machine and check the exact JSON fields to see if it missed any data, tracking the raw accuracy scores while a real human sits there and grades the tone. Check the math.
You have to check the guardrails. A bot that writes beautiful English but immediately hands out free refunds to scammers is a complete disaster—so you test it by trying to break its rules.
| Evaluation area | What to check | Example metric |
|---|---|---|
| Task accuracy | Does it actually work? | Math scores. |
| Format reliability | Does it break the JSON? | Schema checks. |
| Factual safety | Does it make things up? | Fact checks. |
| Policy compliance | Does it break the rules? | Audit logs. |
Safety, Privacy, and Compliance
Scrub the files immediately. If you accidentally leave a single social security number or API key in the training spreadsheet, the machine will absolutely memorize it and gladly hand it out to a random user later. Delete the secrets.
Lock down the server folders. The finished code patch literally holds your entire internal business logic, so you treat those files like highly classified company secrets instead of dumping them on an open GitHub repo.
Never let it click send. You can let the machine draft the rejection letter or the medical bill, but you absolutely force a living human to click the final approval button—which you can map out using Codeayan’s piece on human-in-the-loop governance.
Deployment and Monitoring
Roll it out slowly. You run the bot in the background—letting it guess the answers while a human actually does the job—and you only flip the switch to live production after it goes a full month without screwing up. Watch it closely.
Track the server bills. You log every single API crash, check the exact second it takes to respond, and ask the customer service team if the new bot actually saved them any time at all.
It rots over time. The company changes the rules, the slang evolves, and the bot slowly turns into an outdated mess—forcing you to gather brand new data and run the expensive training loop all over again.
Common Mistakes in Fine Tuning LLMs
Stop rushing the math. People get a terrible answer from ChatGPT and instantly try to build a custom neural network when they really just needed to write a slightly better text prompt.
You cannot train on garbage. If your database is full of lazy employees giving terrible advice, the script will just learn how to act exactly like a lazy employee.
Stop grading the grammar. A bot that speaks beautifully but hands out the wrong tax codes is completely worthless to a financial firm.
- Do not run the script before you try basic prompts.
- Do not use old chat logs without cleaning them.
- Do not hardcode facts into the brain.
- Do not test it on the same data it studied.
- Do not let it run wild without humans checking the work.
A Practical Decision Framework
Ask yourself the hard questions. Do you actually have a massive pile of perfect data, or are you just guessing? Is the job going to stay exactly the same for the next year? And more importantly—is the server bill actually going to be worth the trouble? Do the math.
If you fail that checklist, stop everything. Go back to basic scripting, hook up a database, or just write a standard python tool instead of burning cash on deep learning.
Key Takeaways
- Fine tuning LLMs completely overwrites the machine’s attitude to force an exact output.
- Do not use this to teach the machine new facts.
- Clean your files—garbage data guarantees a garbage bot.
- Use patches like LoRA to run the math on cheap hardware.
- Test the bot strictly on facts, not just grammar.
- Never let the bot run a corporate workflow without a human supervisor.
Conclusion
This isn’t about building a supercomputer. You just want a machine that punches the clock, formats the JSON exactly right, and follows the rigid company rules without arguing with you. Keep it totally boring.
Hit it with the prompt first. Plug in a search engine for the facts, and only run the expensive training loop when you desperately need the formatting locked down perfectly. Combine them all to win.
Keep pushing the code further. Read Codeayan’s breakdowns on Metaprompting, Model Quantization and Distillation, and Explainable AI.
Further reading: Review the OpenAI supervised fine-tuning guide, the Hugging Face PEFT documentation, the LoRA paper, and the QLoRA paper.