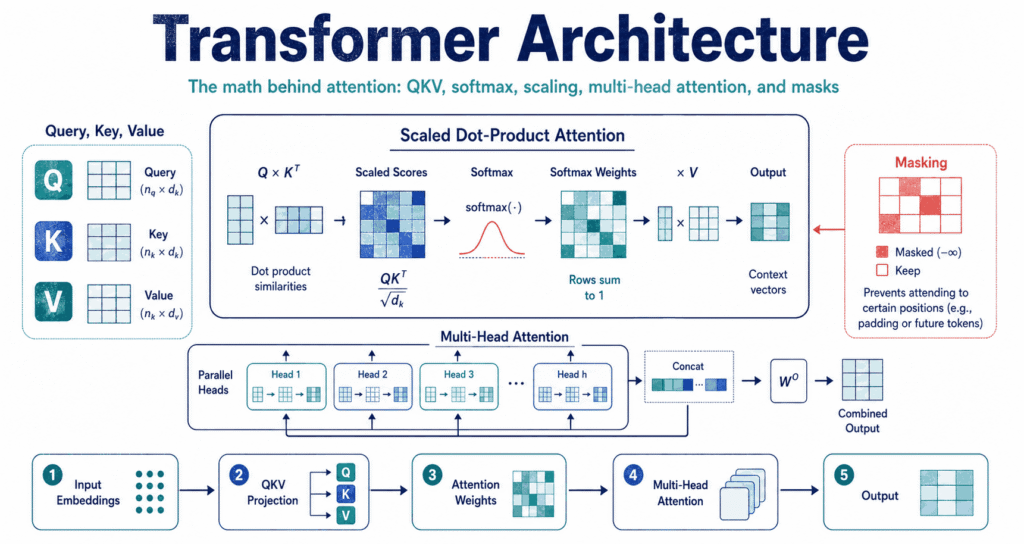
Transformer Architecture completely broke the old rules of deep learning. Gone is the slow crawl of reading text word by word—instead, this setup forces every single token to look around, measure itself against the rest of the sequence, and pull whatever information it actually needs. The math engine running this show is called scaled dot-product attention.
Here is the plan: we break down the attention problem first, hit the Q-K-V setup, walk through the math formula, and then piece together masks and positioning before capping it off with the full block.
The Problem Attention Solves
Language is messy. Take the sentence “The animal did not cross the road because it was tired,” where “it” points right back to “animal”—a connection a computer completely fails to make without some serious help linking ideas across long distances. It needs context.
Older RNN models were slow. They chewed through text step by step, meaning information from the start of a paragraph often washed out by the time the model reached the end. Transformers throw that whole process away. They let every token lock eyes with the rest of the sequence instantly.
This isn’t magic. It is math. A token violently scores its neighbors—ranking them on a strictly numerical basis—before converting those raw scores into probabilities and blending the entire sequence together.
Attention in One Formula
Look at the core math:
Queries ask. Keys match up to them, and values hold the actual data you want to mix together at the end.
Do not let the short formula fool you, because it hides the entire engine of the system—first you compare your queries with your keys, scale the results down, run a softmax to get your weights, and finally smash those weights together with your values. It acts as a workhorse.
In plain English? Figure out who cares about who. Every single token calculates exactly how much it should value its neighbors before building an entirely new state using those customized weights.
Understanding Q, K, and V
Think of Q, K, and V as Query, Key, and Value. They all spawn from the exact same input tokens but get pushed through separate matrices during training—meaning one single token suddenly gets to wear three entirely different hats. It multi-tasks.
A query is what a token wants. The key acts as an ID badge showing what the token offers, while the value holds the payload—the actual data passed down the line if a match fires off.
| Symbol | Name | Intuition | Role in attention |
|---|---|---|---|
| Q | Query | What the token wants. | Checked against all keys. |
| K | Key | Its ID badge. | Used to run the numbers. |
| V | Value | The actual payload. | Mashed together for the output. |
This split makes total sense. A word might be great for matching a context but hold completely different data for the actual output, and the network figures out how to juggle these roles while it runs through training.
Step 1: Dot Products Measure Similarity
That QKᵀ part just measures similarity. If a query and key point the same way in vector space, you get a huge number—but if they have absolutely nothing in common and point in opposite directions, the dot product shrinks down to almost nothing. Math finds the connections.
Picture five tokens. They each spit out a query and a key, and multiplying them gives you a 5×5 grid where every row is basically one token shouting across the board, “Who here actually matters to me?”
Attention Score Computation
Embeddings
Projections
V
Scores
Weights
Dot products are cheap. GPUs eat matrix multiplication for breakfast, which is exactly why this setup trains fast instead of bottlenecking like the old word-by-word models did.
Step 2: Why Divide by √dₖ?
People ignore the √dₖ scaling term constantly. Don’t do that. Here, dₖ is the dimension of the key vectors, and as those vectors bulk up, the raw dot products can blow up into massive numbers if you do not step in and control them.
Big numbers break the softmax. It gets too sharp—dumping 99% of the attention onto a single word while ignoring the rest—which completely stalls out your gradients and makes the training process fall apart.
Dividing fixes it. The math still means the same thing.
Math check: scaling cools things down. It stops the numbers from going off the rails before the softmax hits.
Step 3: Softmax Turns Scores into Weights
Next comes the softmax. It forces all those raw, messy numbers to behave like probabilities where every row adds up perfectly to 1—forcing each token to divvy up its attention budget across the whole sequence. It plays fair.
If word A loves word B, the score shoots up. If word C is garbage, its weight drops to near zero.
You can think of it as a weighted average, but that sounds boring. It is really the model pulling bits and pieces from all over the place to build a custom blend for each specific word.
Step 4: Values Carry the Information
Slapping that V on the end gets you the final output. The weights from earlier act as a bouncer, deciding exactly how much of each value vector actually makes it into the final mix for any given word.
Now you have context. The token is not stuck in a vacuum anymore.
That right there is self-attention in a nutshell. Every piece of text looks around the room, picks up on the vibe from its neighbors, and updates its own state to match what is going on.
Self-Attention vs Cross-Attention
In self-attention, your Q, K, and V all pull from the same pool. Encoders and decoders abuse this constantly.
Cross-attention flips the script entirely by pulling queries from one sequence while stealing keys and values from somewhere else—a setup you see all the time in translation tasks where the decoder reaches back into the source sentence to figure out what to say next.
| Attention type | Where Q comes from | Where K and V come from | Use case |
|---|---|---|---|
| Self-attention | Same input | Same input | Figuring out local context. |
| Cross-attention | The target output | The source input | Bridging the gap between two sequences. |
Multi-Head Attention: Why One Attention Is Not Enough
One attention pass only finds one pattern. But language is a mess of grammar rules, slang, and weird dependencies, so relying on just one pass is a terrible idea—you need one head looking for verbs, another hunting down pronouns, and maybe a third just trying to figure out where the commas go.
Multi-head setups run a bunch of these in parallel. Every head gets its own matrices.
Every head gets a totally different look at the data.
Diversity is the whole point here. Instead of forcing all the math through one tiny bottleneck, the system lets a dozen different heads go digging for whatever weird patterns they can find.
Attention Masks: Controlling What a Token Can See
Letting tokens see everything is great—until it ruins your model. When you generate text, letting the system peek at future words is straight-up cheating.
Masks fix the cheating problem by slapping a massive block on future positions—meaning the model can only look backward—which is the only way autoregressive generation actually works in the real world.
Then you have padding masks. You tell the model to ignore the empty space.
- Causal mask: stops the model from cheating by looking ahead.
- Padding mask: hides the blank filler text.
- Custom mask: forces specific rules on what gets seen.
Where Positional Encoding Fits
Attention is completely blind to order. If you scramble a sentence like a deck of cards, the raw math does not care at all—which is a massive problem when you are dealing with actual human language where order means everything.
Positional encoding acts like a timestamp. The old paper used sine waves, but modern setups often just let the model figure out the positions on its own—or they use newer rotary tricks to get the job done.
Attention finds the meaning. Position finds the spot.
The Transformer Block Around Attention
Attention gets all the hype. But an actual block wraps that attention inside a messy sandwich of residual connections, layer normalization, and a feed-forward network just to keep things stable.
The attention layer mixes the data, while the feed-forward section processes each token entirely on its own—and those residual connections act like a bypass valve to keep the math from dying out before it reaches the end.
Simplified Transformer Block
Embeddings
Attention
Norm
Network
Norm
Stack them up. The early layers pick up on basic grammar, while the layers near the top start figuring out sarcasm and deeper concepts.
A Minimal Attention Implementation
Look at this PyTorch code. It strips away all the bloat and leaves just the raw math engine running the show—nothing fancy, just the bare minimum to make it work.
import torch
import torch.nn.functional as F
import math
def scaled_dot_product_attention(Q, K, V, mask=None):
# Q: [batch, heads, query_len, d_k]
# K: [batch, heads, key_len, d_k]
# V: [batch, heads, value_len, d_v]
d_k = Q.size(-1)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-inf"))
attention_weights = F.softmax(scores, dim=-1)
output = torch.matmul(attention_weights, V)
return output, attention_weights
That short script does everything. You multiply matrices, scale the numbers, drop the mask on top, run the softmax, and mix the final values together.
The Shape of Attention
Tensor shapes trip people up constantly. If you throw in n tokens and your keys have a dimension of dₖ, you end up with an n × n grid once you multiply Q and Kᵀ together.
That n × n grid is terrifying for your memory. It literally forces every single word to score itself against every other word, meaning if you double the length of your text, your memory cost blows up by a massive factor of four.
Long context breaks things. Engineers spend all day trying to hack this memory problem.
Common Misunderstandings About Attention
Let’s clear something up right now—attention is not an explanation. Just because a model stared at a specific word does not mean that word actually caused the final output, no matter how much you want it to make sense.
Attention does not understand anything. It is a dumb filter.
Also, multi-head setups do not just copy-paste the same math over and over again—every single head gets its own matrix weights so it can hunt for completely different things in the text.
Why the Math Matters
Do the math. If you actually look at the equations, you stop guessing why your server bill spikes on long prompts or why your text generation turns into garbage when the mask breaks.
It saves you hours of debugging. Once you stop treating Q, K, and V like magic and see them for what they are, reading new papers goes from a headache to a breeze.
Connect this to logic pipelines by checking out Codeayan’s breakdown on Chain-of-Thought Prompting. Or jump into ReAct prompting for agent setups.
Key Takeaways
- Transformer Architecture ditches old sequential reading—letting tokens swap data directly.
- The core formula is Attention(Q,K,V) = softmax(QKᵀ / √dₖ)V.
- Queries want data, keys act as IDs, and values hold the payload.
- Scaling by √dₖ stops the math from exploding.
- Multi-head setups let the system hunt for dozens of patterns at the exact same time.
- Masks act like blinders to stop the model from cheating.
Conclusion
This math turns context into simple multiplication. The network skips reading left-to-right entirely—instead, it builds a massive web of scores and extracts whatever data it needs on the fly.
Every single variable pulls its weight. QKᵀ checks the relevance, the square root locks down the stability, the softmax distributes the weights, and V drops in the actual data.
Grasp this, and the whole architecture clicks. Everything from multi-head setups to giant modern models boils down to one simple idea—let the tokens figure out what matters on their own.
Further reading: Dive into the Attention Is All You Need paper, check out The Annotated Transformer, or hit the PyTorch scaled dot-product attention documentation.