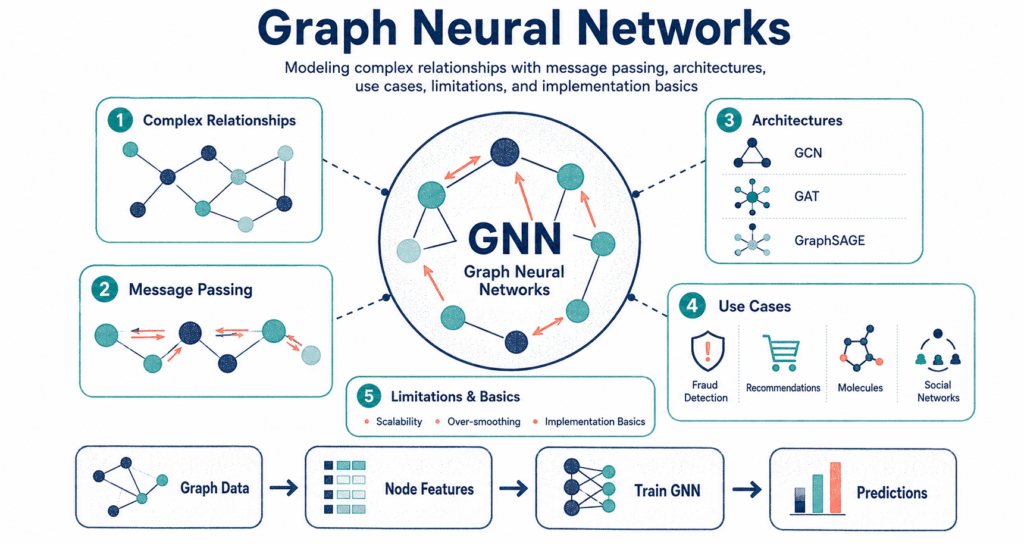
Graph Neural Networks completely toss out the old spreadsheet mentality where every row sits in total isolation. They track the actual connections between things – whether you are mapping out chemical bonds or hunting down a massive credit card theft ring – and pass data across that messy web of nodes and edges to figure out the truth. Connect the dots.
Why Graph Neural Networks Matter
Real life absolutely refuses to fit into clean rows and columns. A massive money laundering scheme is never just a list of random bank accounts – it is a deeply connected web of shared burner phones, fake addresses, and fast cash transfers crossing borders in seconds. Stop flattening the world.
Standard models demand tables. You feed them rows and completely destroy the actual network data unless some poor engineer spends weeks hand-coding custom rules to track the wires.
Graph Neural Networks read the raw web directly. They blend what an object is with who it talks to – meaning an account might look totally fine on paper until the network realizes it shares a device ID with ten known scammers.
The main idea: stop asking what something is. Ask who it hangs out with, how money moves between them, and what the surrounding neighborhood looks like.
What Is a Graph?
Graphs are just math maps. You get dots and lines – which data scientists prefer to call nodes and edges – and these lines can run one-way, both ways, or carry heavy weights depending on how often two people actually talk to each other. Watch the flow.
Think about Twitter. If you follow someone, that is a one-way street, but a Facebook friendship forces a two-way connection.
The magic happens when the connection itself holds the answer. You might buy a weird niche product simply because three of your closest friends bought it yesterday.
| Graph element | Meaning | Example |
|---|---|---|
| Node | The thing itself. | Users, atoms, bank accounts. |
| Edge | The wire connecting them. | Sending cash, following a profile. |
| Node feature | Data about the thing. | Age, account balance, chemical type. |
| Edge feature | Data about the wire. | Dollar amounts, distance in miles. |
Why Traditional Models Struggle with Graph Data
Old algorithms assume your data rows have absolutely nothing to do with each other. This falls apart instantly in the real world. A buyer might look like an average shopper until you realize they share a shipping address with a massive ring of stolen credit cards.
The shapes change constantly. Images lock into a strict pixel grid and text runs in a straight line, but a graph can have one node talking to two neighbors while the guy next to him screams at five million followers simultaneously.
Because the shape is a complete mess, you need an engine that ignores the exact order of the data. Swap node 1 with node 900, and the math should still spit out the exact same answer at the end of the run.
The Core Idea: Message Passing
Message passing runs the whole show. Every single node looks at its neighbors, sucks up their data, mashes it together, and updates its own identity before the next round starts. Two rounds in, and you suddenly know what your neighbor’s neighbor is doing. Gossip spreads fast.
This matters because the real threat is usually hiding two hops away. A money launderer won’t wire cash directly to the kingpin – they bounce it through five shell companies first.
How Nodes Gossip
Features
Messages
Messages
Embedding
Layer
You need a math function that handles any random number of neighbors. You sum them up, take the average, or run attention weights, and then a neural network scrambles that neighborhood gossip into a fresh embedding.
The takeaway: the network builds an identity for each dot that blends its personal stats with the street reputation of its neighbors.
Node, Edge, and Graph-Level Tasks
You can aim these networks at completely different targets depending on what you actually want to figure out. Sometimes you care about the dot, sometimes you care about the wire, and sometimes you care about the entire web. Pick your battle.
Node targets sort individuals. You flag a single account as a bot. Edge targets guess connections – like figuring out if a user will click a specific ad tomorrow. Graph targets look at the whole picture to guess if a new protein structure will cure a disease or just turn into toxic sludge.
| Task type | Prediction target | Example use case |
|---|---|---|
| Node classification | Sorting the dots. | Spotting fake users. |
| Link prediction | Guessing the wires. | Recommending a video. |
| Edge classification | Sorting the wires. | Flagging bad wire transfers. |
| Graph classification | Sorting the whole web. | Guessing if a chemical is poison. |
Popular GNN Architectures
There is no single master algorithm here. People built dozens of different architectures to figure out exactly how nodes should mash neighbor data together without breaking the math.
Graph Convolutional Networks (GCNs) started the hype by giving engineers a surprisingly cheap way to run neural networks directly over messy graph data. They basically smear information across the network using a normalized matrix.
GraphSAGE fixed the new-data problem. Instead of memorizing the whole map, it learns a set of rules to pull neighbor data – which means you can drop a brand new user into the system tomorrow and it won’t crash the server.
Graph Attention Networks (GATs) let nodes play favorites. Not every neighbor matters. If you are hunting a credit card thief, the shared burner phone matters infinitely more than the fact that they both bought coffee at Starbucks yesterday.
| Architecture | Main idea | Useful when |
|---|---|---|
| GCN | Smeared neighbor data. | You just want a basic starting point. |
| GraphSAGE | Rule-based pulling. | Users join your app every five seconds. |
| GAT | Playing favorites. | Some connections are absolute garbage. |
| Heterogeneous GNN | Mixing apples and oranges. | You have ten different types of data colliding. |
Graph Embeddings: The Output of Representation Learning
The whole point of this exercise is spitting out a dense string of numbers. We call them embeddings. An embedding locks a node’s personal stats and its entire neighborhood history into one tiny math vector. It compresses reality.
You take that string of numbers and feed it to a dumb classifier to get your final answer. You can compare two vectors to see if people should date, or feed a whole graph vector into a system to check if a drug works.
It mimics word embeddings. But instead of just looking at the words next to it in a sentence, the math maps out exactly where the dot lives inside a massive, tangled web of relationships.
A Small PyTorch Geometric Example
Nobody writes this math from scratch anymore. You just pull PyTorch Geometric off the shelf and start stacking layers.
Look at this bare-bones code. It hides the complexity, but you can clearly see how the raw features mix directly with the edge index map to force the data through the network.
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
class SimpleGCN(torch.nn.Module):
def __init__(self, num_features, hidden_channels, num_classes):
super().__init__()
self.conv1 = GCNConv(num_features, hidden_channels)
self.conv2 = GCNConv(hidden_channels, num_classes)
def forward(self, x, edge_index):
# x: raw node data [num_nodes, num_features]
# edge_index: the wire map [2, num_edges]
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, p=0.5, training=self.training)
x = self.conv2(x, edge_index)
return x
model = SimpleGCN(
num_features=16,
hidden_channels=32,
num_classes=3
)
A real project adds a ton of boilerplate. But the heartbeat is exactly this – node data and connection wires slamming into graph convolution layers at the exact same time.
Where Graph Neural Networks Are Used
Drop these models into any problem where the connections actually matter. They dominate product recommendations, drug discovery, massive fraud rings, and even predicting traffic jams on highways. Use them where the map matters.
E-commerce sites track the mess. A graph hooks up your late-night searches with your past purchases, mapping your behavior against millions of other buyers to figure out exactly which shoe you will buy next.
Fraud is a network game. Scammers rarely work alone. They share devices, fake addresses, and bank routing numbers, creating massive clusters of lies that a GNN spots instantly while a standard model just sees a bunch of independent, normal-looking transactions.
Chemicals are just graphs. The atoms act as dots and the bonds act as wires.
Traffic jams spread like a virus. A crash on the highway ripples out, and a graph model tracks that wave across intersections to warn drivers miles away.
GNNs and Complex Relationships in Business Problems
This isn’t just theory for academics sitting in a lab. Real companies use this math the second their data gets tangled up in relationships.
Banks hunt money mules this way. A guy wiring fifty bucks looks completely innocent until the network proves that fifty bucks bounced through six different accounts and landed in an offshore shell company. The context exposes the crime.
B2B sales teams run the exact same play. A single buyer connects to parent companies, weird subsidiaries, and past partners.
It spots the weird stuff. If you want to see how to flag weird data in general, go read Codeayan’s breakdown on anomaly detection in high-dimensional data.
Homogeneous vs Heterogeneous Graphs
Simple maps stick to one type of dot and one type of wire. A bunch of scientific papers linking to other papers makes the math incredibly easy to run.
But real business data mixes everything up. Amazon has users, products, reviews, shipping centers, and search terms all colliding in the same space. Treating a five-star review exactly the same as a shipping manifest completely destroys the value of the data.
Heterogeneous models fix this mess. They keep the data types separated so the system actually understands the difference between a user buying a product and a warehouse shipping it out.
| Graph type | Structure | Example | Modelling concern |
|---|---|---|---|
| Homogeneous | Basic. | Papers citing papers. | Easy math. |
| Heterogeneous | Apples and oranges. | Amazon’s entire database. | You have to separate the rules. |
| Dynamic | Moving targets. | Twitter feeds. | Do not cheat with future data. |
Common Challenges in GNN Projects
Don’t just blindly throw a GNN at your database. Building the actual map is a nightmare. You have to decide what gets a dot, what gets a wire, and when to cut off old data before the whole thing turns into a useless hairball.
Size kills servers. You cannot fit a billion-edge Facebook graph into standard GPU memory. You end up slicing the map into pieces and praying the math still holds up.
Testing is a trap. If you randomly split your data, you will accidentally leak future connections into your training set and trick yourself into thinking your model is a genius. You have to split by time.
Stacking too many layers ruins the output. The data smears together until every single dot looks exactly the same.
- Map design: terrible wiring kills the project instantly.
- Server limits: big maps will melt your GPU.
- Cheating: don’t let future data sneak into your training sets.
- Blurring: too many layers turns all your data into gray sludge.
- Black boxes: good luck explaining the math to your boss.
Explainability in Graph Neural Networks
People hate black boxes. When you deny a loan or flag an account, the compliance team will literally kick down your door asking exactly why the machine made that call.
It is a massive headache. Did the system flag the user because of their own bank history, or because their third cousin once wired money to a known criminal?
You end up digging through subgraphs to find the specific wire that triggered the alarm. For the bigger picture on opening up black boxes, check out Codeayan’s guide on Explainable AI.
How to Start a GNN Project
Do not start with the math. Look at your problem and figure out if the connections actually matter, because if a standard random forest model already hits 95% accuracy, building a GNN is just an expensive waste of time.
Draw the map first. Figure out your dots and wires.
Run a dumb baseline. Train a basic model and use it to prove that the fancy graph math actually adds value to the company.
Practical GNN Project Workflow
the issue
the map
the data
dumb test
real math
Best Practices for Modelling Complex Relationships
Stop drawing useless lines. Just because two users logged in on the same day does not mean they need a wire connecting them. Garbage connections drown out the actual signal.
Do not cheat time. If you want to catch tomorrow’s credit card thieves, train on last month’s data and test on this week’s logs.
Keep it shallow. Most of the best models only use two or three layers.
- Wire it right: only connect things that actually matter.
- Test the dumb stuff: prove the fancy math beats a basic spreadsheet.
- Watch the clock: don’t leak future answers.
- Watch the memory: it balloons fast.
- Dig around: figure out exactly who triggered the alarm.
- Ship it carefully: live maps break easily.
GNNs vs Other Deep Learning Models
Images love grids. Text loves straight lines. Graphs handle the absolute chaos where connections dictate reality.
You don’t have to pick just one. You can run an image through a standard CNN, pull the objects out, and wire them up in a graph to figure out what is happening in the scene.
Mash them together. The smartest systems look at the text, the images, and the network wires all at once to make a call.
Deployment Considerations
Shipping this code is miserable. With a normal model, you pass one row of data and get one answer. With a graph, you have to pull the user, grab their neighbors, check the active wires, and run the math in real-time.
Most teams cheat. They run the math overnight, save the embeddings, and just look them up the next day. It is incredibly fast, but your data is always twenty-four hours out of date.
Squeeze the models down. Look at Codeayan’s piece on model quantization and distillation if you need to jam these heavy networks onto smaller hardware.
Common Mistakes to Avoid
Hype kills projects. Do not build a GNN just because you read a cool paper on Twitter last week.
Bad maps equal bad answers. If you hook up every user who bought milk in the last year, your map turns into a giant ball of yarn that teaches the model absolutely nothing.
Stop shuffling the rows. If you randomly split your test data, you will leak the answers and completely humiliate yourself when you push the code to production.
- Skip the hype: you might just need a basic database.
- Stop drawing random lines.
- Track the flow and the clock.
- Beat the real models first.
- Stop shuffling time-sensitive logs.
Key Takeaways
- Graph Neural Networks jump in when the connections matter more than the raw data.
- Dots are the entities, wires are the relationships, and the math maps it all out.
- Nodes constantly gossip with their neighbors to build a better profile.
- You can guess the dots, guess the wires, or guess the entire web.
- GCN, GraphSAGE, and GAT give you different ways to smear the data around.
- Do not cheat time, watch your server memory, and make sure your connections actually mean something.
Conclusion
This math completely changed the game because real life is just a massive web of relationships. Users hook up to products, banks hook up to shell companies, atoms hook up to molecules, and a flat spreadsheet simply cannot see the big picture.
Nodes suck up their neighbors’ data. The network figures out who you are by looking at who you hang out with, which makes these models perfect for catching fraud rings, recommending products, and discovering new drugs.
Keep your head on straight. Draw a clean map, run a basic test first, and only roll out the heavy graph math when you absolutely have to trace the wires to find the truth.
Further reading: Review the Graph Convolutional Networks paper, the Graph Attention Networks paper, the GraphSAGE paper, and the PyTorch Geometric documentation.