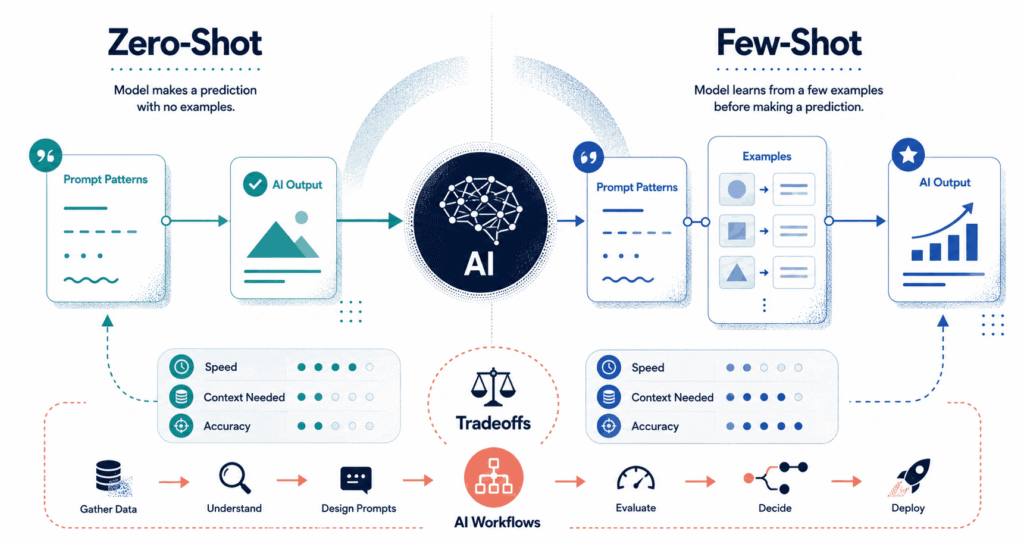
Zero-shot and few-shot learning let machines figure out brand new jobs without drowning in labeled data. You stop hoarding massive CSV files full of tagged examples – instead relying entirely on writing a brutally clear set of instructions with maybe two or three quick demonstrations tossed in just to keep the neural network from totally losing its mind. It skips the grind.
The Core Idea: Learning Without Full Retraining
Old school machine learning demands a massive pile of tagged data. If you need a script to read angry tweets and flag them, you normally pay a team to sit there and manually grade ten thousand separate messages before you even think about booting up a training loop or checking the validation scores. It eats up months.
These new methods completely trash that old workflow. The network already swallowed half the internet during its base training run – so your only real job is setting up the exact right prompt to force the machine to connect its hidden memory banks directly to your specific problem. Look at image models running CLIP – they just map text to pixels instantly.
You move incredibly fast. You can stand up a working data scraper or a document summarizer in an afternoon without burning fifty grand on a custom GPU training job just to see if the idea actually makes sense. But here is the catch – if your instructions are even slightly confusing, the output turns to absolute garbage.
Instruction
Examples
Model
Output
The reality check: zero-shot lives or dies on how you write the rules. Few-shot survives entirely on how good your examples are, but both will completely crash if you ask the bot to do something vague.
Two Meanings People Often Mix Up
People mix these terms up constantly. The old data science crowd uses the phrase to describe an image scanner guessing a completely new category it never saw during training – while the prompt engineering guys just use it to mean typing a question into a text box without holding the machine’s hand. Two different worlds.
The confusion gets worse with the next term. Academics write papers about updating model weights using fifty pictures of a cat, but regular developers just drop three example emails directly into the chat window and call it a day. Focus on the text box version.
| Context | Zero-shot means | Few-shot means |
|---|---|---|
| Classical ML / vision | Guessing new categories using math vectors. | Tweaking the actual brain weights with a tiny dataset. |
| LLM prompting | Typing strict rules into the chat box. | Typing the rules and pasting three good answers right below them. |
You have to know the difference to survive a meeting. An academic paper dives deep into mathematical vectors and class boundaries – but the guy building a customer service bot just wants to know exactly how to structure the text prompt so the script stops handing out wrong answers. They just want the code to work.
Zero-Shot Learning Techniques
You give the machine absolutely nothing to copy. You just type out the raw rules and expect the system to figure out the rest on its own – which actually plays out totally fine if the job is boring and the final output is just a single word. Keep the ask tiny.
A solid script breaks down into four hard pieces. You assign it a fake job title, explain the exact chore, throw up a massive wall of things it is absolutely forbidden from doing, and force it to spit out the answer in a specific format so your background code can actually read it. Box it in.
You are a support ticket classifier. Classify the ticket into exactly one label: Billing, Technical, Account, or Other. Return only the label. Ticket: "I was charged twice for the same subscription renewal."
Look closely at those specific category names. If you use weird internal codes like “Cat-4” instead of just saying “Billing,” the machine will completely lose its mind and guess blindly – because it relies heavily on the actual dictionary definition of the word to figure out where the email belongs. Words hold power.
You pair this up with negative prompting techniques to shut the bot up. When the system desperately tries to write a three-paragraph apology letter for every single support ticket, you just aggressively order it to drop the conversational filler and return the raw data. Kill the noise.
Few-Shot Learning Techniques
Now you hand over the cheat sheet. You paste a handful of perfect inputs and outputs right into the text window, forcing the machine to mimic the exact pattern you laid out – which is the entire premise backing the famous Language Models are Few-Shot Learners paper that kicked off this whole obsession. It copies you.
But here is the catch – you are not actually training the machine at all. The internal math of the brain stays completely frozen while you run the prompt, meaning the system just uses your pasted examples as a temporary reference guide that gets completely wiped from memory the second the run ends. It resets instantly.
Classify each message as Positive, Negative, or Neutral. Return only the label. Message: "The dashboard loads quickly and the charts are clear." Label: Positive Message: "The export button fails every time I try to download data." Label: Negative Message: "The new report is available in the analytics tab." Label: Neutral Message: "The search feature is much better after the update." Label:
Those three lines dictate the entire reality of the script. They lock down the attitude, force the JSON formatting, and draw a hard line in the sand – so if you only feed the prompt incredibly easy examples, it will completely panic the second a user types something weird in production. Test the edges.
You mix these examples up with Chain-of-Thought Prompting when the math gets hard. If the script has to figure out a complex logic puzzle before spitting out an answer, you literally write out the scratchpad math for it – but if you just need it to pull an email address out of a text block, you skip the logic and keep the examples brutally short. Be brief.
Zero-Shot vs Few-Shot vs Fine-Tuning
The choice comes down to your server bill and your patience. You do not burn fifty dollars fine-tuning a custom network just because some guy on Twitter said it was the future – you always start with the dumbest, cheapest prompt possible and only scale up when the script actually fails. Save your money.
| Method | What you provide | Best for | Main limitation |
|---|---|---|---|
| Zero-shot | The raw rules | Fast tests and single-word answers | Completely bombs out on weird requests |
| Few-shot | Rules plus three good examples | Forcing strict JSON layouts | Eats up your token limit fast |
| Fine-tuning | A massive CSV and a training run | Heavy enterprise jobs running thousands of times a day | A total nightmare to update when rules change |
| RAG + Prompting | Rules plus a database search | Jobs requiring the company’s private files | A bad search returns a terrible answer |
How to Design Strong Few-Shot Examples
Lazy examples destroy good scripts. A developer will casually drop three totally identical positive reviews into the text box, completely forgetting to show the machine what a negative review actually looks like – and then they act shocked when the bot blindly approves a furious customer complaint in production. Show the contrast.
You have to map out the gray areas aggressively. You throw in a glowing review, a screaming rant, and a totally weird back-handed compliment just to show the machine exactly where you draw the line – and you make absolutely sure every single one of them shares the exact same formatting. Lock it down.
- Keep it brief: don’t write a novel.
- Lock the layout: copy-paste the exact structure.
- Test the boundaries: throw weird stuff at it.
- Mix the answers: don’t just use positive hits.
- Use real logs: stop making up fake user quotes.
The hidden trap: order dictates the outcome. If you stick a totally bizarre edge case at the very bottom of the list, the machine will latch onto that specific weirdness and apply it to every single answer it generates.
Practical Applications
You pull these tricks out when your boss demands a working prototype by Friday and you have absolutely zero historical data to work with. They let you fake a massive backend system entirely through clever text files while the engineers desperately try to build the actual infrastructure behind the scenes. Move fast.
These setups eventually get wired into massive pipelines. When you get tired of typing out the exact same rules fifty times a day, you read up on metaprompting for large-scale model control and learn how to write a script that automatically writes the prompts for you. Automate the writing.
A Simple Build Workflow
Stop overcomplicating the initial build. You write a painfully basic zero-shot rule, run it until it completely fails on a weird user input, and then you take that exact failure and paste it back into the prompt as a permanent few-shot example. You fix the leaks as they happen.
Then you lock the doors. You dump all your test questions into a spreadsheet and force the script to answer them every single time you tweak a word – because adding a new rule to fix one bug almost always breaks three older rules you forgot about. Guard your progress.
Evaluation: Do Not Trust a Good Demo
Demos lie constantly. Just because the bot nailed the first three questions you threw at it does not mean it is ready for production – you absolutely have to slam it with at least fifty brutal edge cases before you even think about deploying the code. Test it hard.
The numbers have to mean something. If you are pulling names out of a text block, you grade the machine strictly on whether it grabbed the exact string of letters without adding weird punctuation marks. Track the raw math.
The penalty for screwing up matters. If your movie review bot drops the ball, no one cares – but if your automated hospital script mislabels a patient file, you are going to get sued into oblivion.
Common Mistakes to Avoid
The problem is treating the text box like a crystal ball. The machine cannot read your mind – it literally just calculates the next most likely word based on the letters you typed, meaning a lazy set of instructions guarantees a completely chaotic response.
- Using bad names: “Level 1” means nothing, but “Critical Fix” gives the bot a massive hint.
- Stuffing the box: pasting fifty examples just confuses the machine and burns your token budget.
- Sloppy layouts: changing the comma placement halfway through the examples breaks the JSON.
- Ignoring the definitions: the bot relies heavily on the actual dictionary meaning of your tags.
- Skipping the tests: changing a comma in the rules can destroy the entire pipeline.
When Should You Use Each Technique?
Start with zero-shot when the job is brain-dead simple and nobody gets fired if it breaks. You step up to few-shot the second you need the machine to output a perfectly structured table, and you only break out the expensive fine-tuning scripts when the company decides the workflow is completely permanent. Escalate slowly.
The smartest engineers build a ladder. You write the cheap prompt first, patch the holes with a few pasted examples, log the failures in a spreadsheet, and only ask the boss for a cloud computing budget when the text box finally hits a wall.
| Situation | Recommended starting point | Reason |
|---|---|---|
| Common task with clear labels | Zero-shot | The raw words are enough to guide it. |
| Custom tone or output format | Few-shot | You force it to mimic your exact layout. |
| Knowledge changes often | RAG + Prompting | The machine needs to read today’s news. |
| Large-scale stable workflow | Fine-tuning | You bake the rules into the actual weights. |
Key Takeaways
- Zero-shot and few-shot tricks let you skip the massive data-tagging phase entirely.
- You survive zero-shot entirely by writing brutally strict, clear rules.
- Few-shot forces the machine to copy your exact formatting by looking at your examples.
- One weird edge case in your examples teaches the machine more than twenty normal ones.
- Demos mean nothing until you run a real spreadsheet of test questions.
- Never fine-tune a model until the cheap prompts completely fail you.
Conclusion
These tricks are the ultimate cheat codes for spinning up AI tools when you don’t have the time or money to build a massive training dataset. You get insane speed right out of the gate with basic rules, and you lock down the chaotic outputs just by pasting a few good examples into the box.
The secret isn’t typing a five-page essay into the chat window. It all comes down to drawing hard boundaries, picking three flawless examples, logging your failures, and patching the leaks – turning a parlor trick into a bulletproof piece of software.
Start bolting these pieces together. You read up on Chain-of-Thought Prompting and Metaprompting to figure out exactly how to stack these prompt blocks into a massive, unbreakable logic pipeline.
Further reading: Review the Language Models are Few-Shot Learners paper, check out Learning Transferable Visual Models From Natural Language Supervision, and dig into Zero-Shot Learning – The Good, the Bad and the Ugly.